Parallel Algorithms
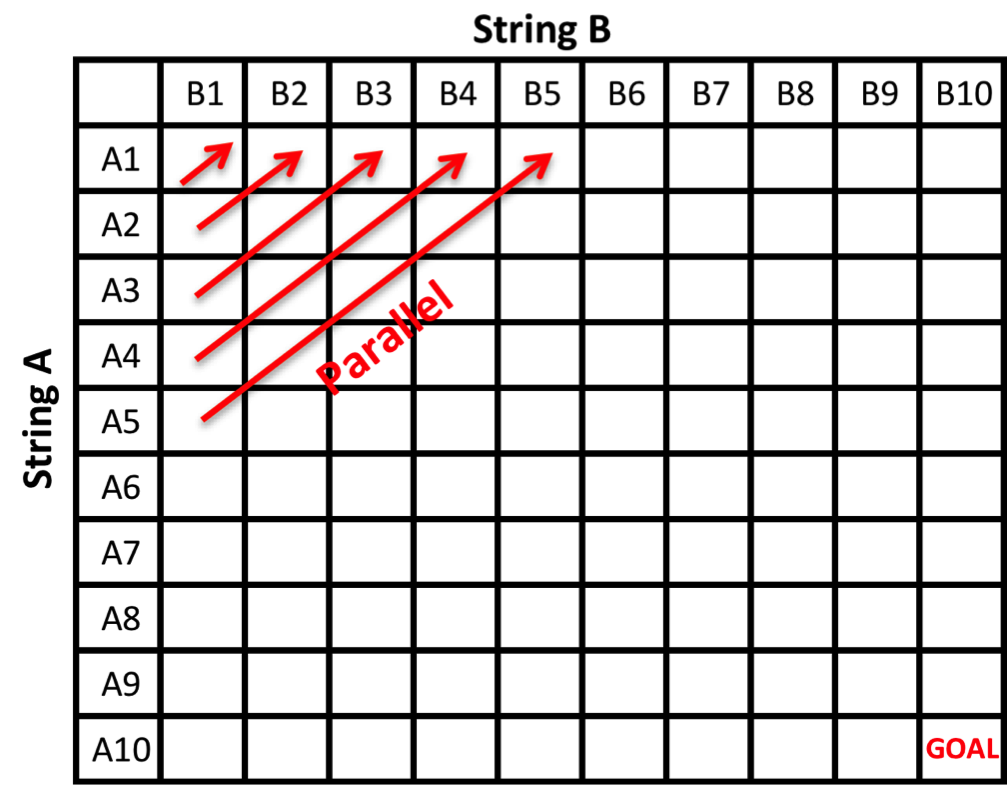
I. Baseline Parallel - No Blocks
In our first parallel NW implementation, we update the alignment matrix along the anti-diagonals in parallel. This is valid due to the particular data dependency of this problem. In each iteration, workers along the anti-diagonal start the computation once the previous anti-diagonal is finished. We only use global memory in this implementation.
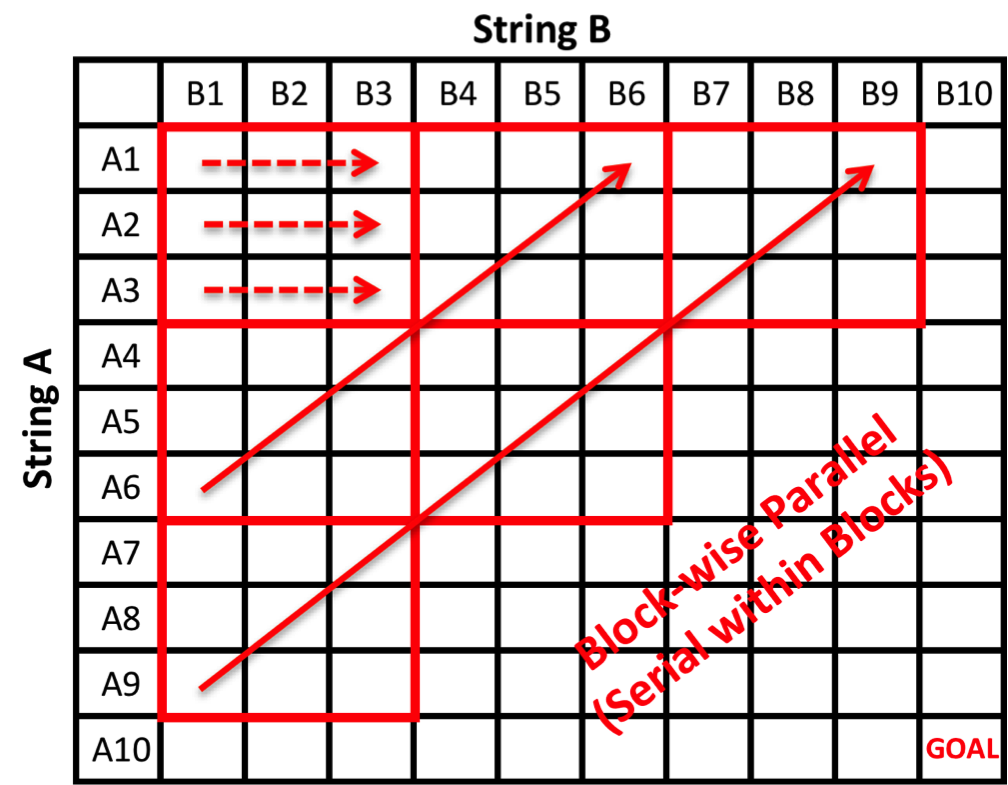
II. Block-wise Parallel - Serial within Blocks
Our second parallel implementation updates the alignment matrix block-wise along the anti-diagonals to take advantage of local memory access. Within each workgroup, we update the alignment matrix using the serial dynamic programming algorithm in local memory.
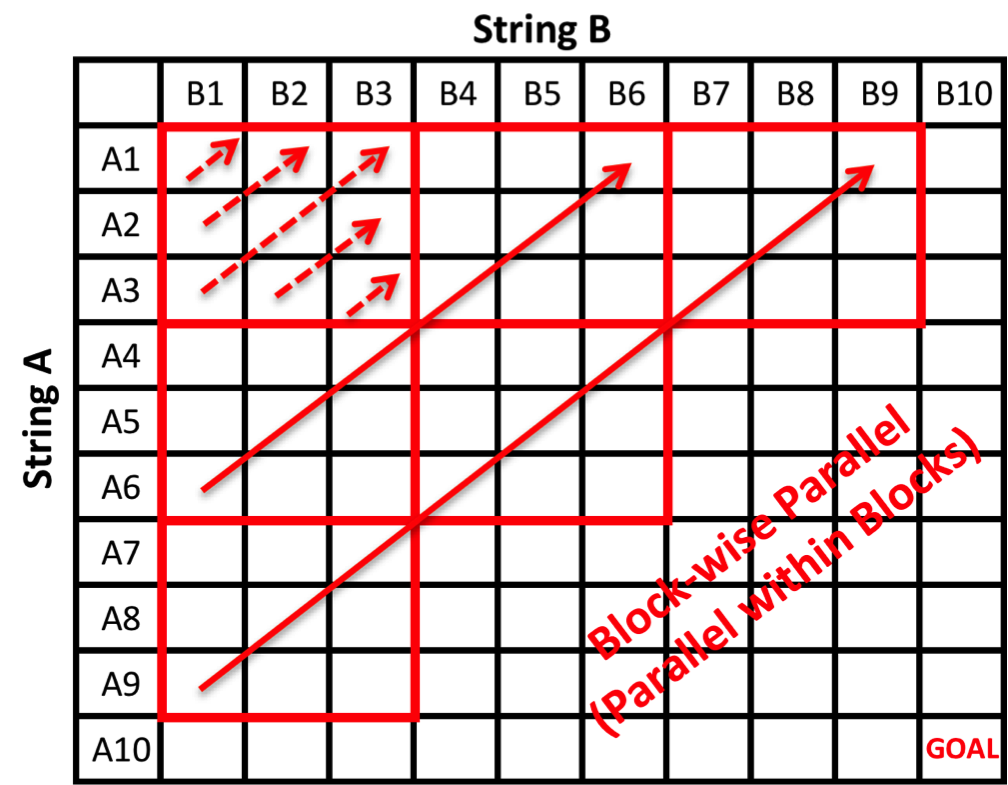
III. Block-wise Parallel - Parallel within Blocks
In our third parallel implementation, we also update the alignment matrix block-wise along the anti-diagonals. However, within each workgroup, instead of using the serial dynamic programming algorithm, we use the parallel NW algorithm along the anti-diagonals in local memory.
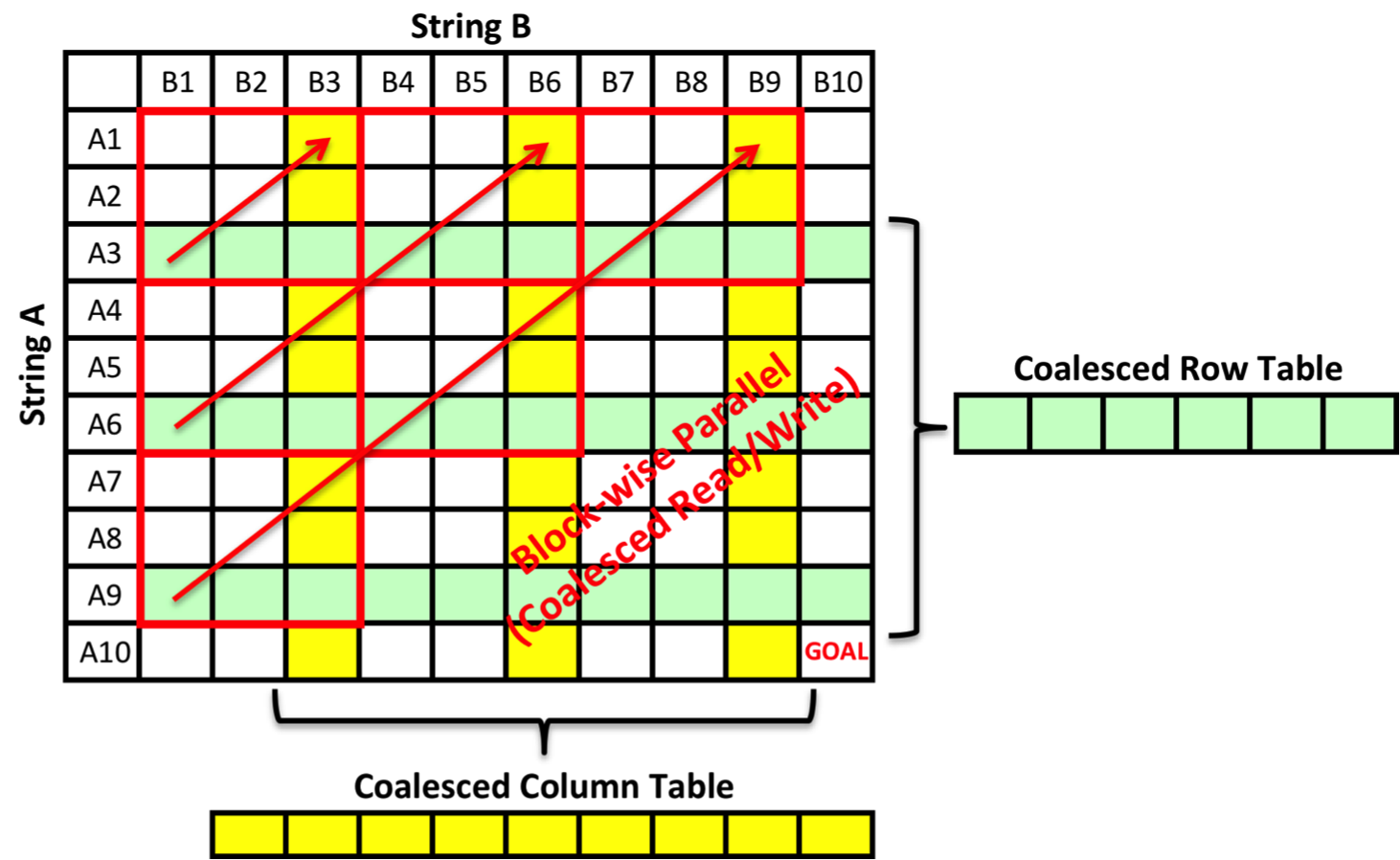
IV. Block-wise Parallel - Coalesced Read & Write
Our final parallel implementation achieves coalesced memory access by saving two tables in global memory for columns and rows on the right of block boundaries, since only these data are required for the next iteration. We expect faster memory I/O with coalesced column reads.